The Role of Error Functions in Machine Learning

Defining Error Functions in Machine Learning Algorithms
In our last blog post on machine learning and mathematics, we defined an error function as follows:
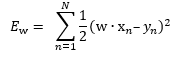
Next, we found a w that minimizes this error function, and we used that w to define our linear function that approximates our target function:
g(x) = w ⋅ x
It is mathematically convenient to define our error function as the Ew shown above to simplify the computation of gradients and allow us to find an analytic solution.
But convenience is only one reason to define Ew in this way. Below, we’ll discuss some of the other important factors that affect how — and why — we use this error function in machine learning algorithms.
Random Variables Can Contribute to Calculation Errors in a Machine Learning Algorithm
In finding g, we assume that for all (x, y) ∈ D, y = f(x), where f is our unknown target function. But in fact, y = f(x) + ε(x), where the function ε comprises all the various errors that can occur. (Remember that we don’t know anything about f — all we have are measurements at specific points.)
In the real world, our measurements are only as good as our instruments, and some of our values might be subjective. From a probabilistic viewpoint, we can consider all the different possible errors to be independent random variables, and so the central limit theorem implies that their sum ε will have a normal probability distribution. This means we can find some σ ϵ ℝ so that:
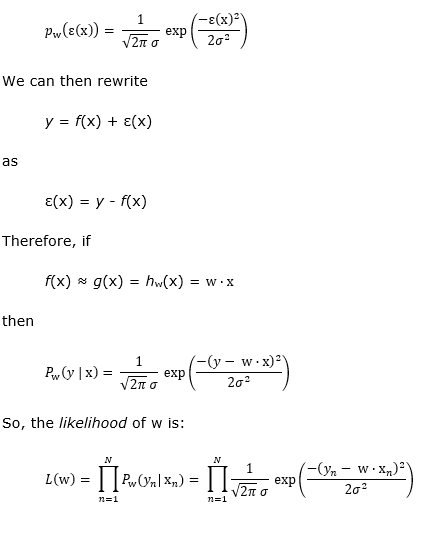
What we want to do is find the w that maximizes this likelihood.
Let l(w) = ln L(w) where ln is the natural logarithm function. Then, maximizing l(w) will also maximize L(w). Let’s compute l(w):
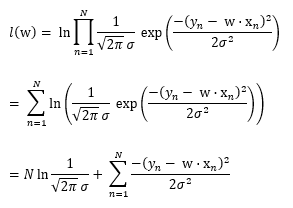
Note that since the term above is a non-negative constant, and because σ2 is also a non-negative constant, we can ignore them for the purposes of finding a maximum value of What we want to find is a w that maximizes the value of:
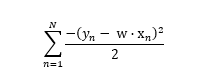
If we multiply by -1 to eliminate the leading minus sign in the summation, the w that maximizes this sum will minimize the corresponding sum:
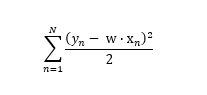
And at this point, you should recognize that this is the same error function that we’ve been trying to minimize all along!
So, not only is our choice of Ew mathematically convenient for our computations, but it also makes sense for finding the w that’s most likely to prove correct.
We’ll continue to explore the fascinating mathematical concepts behind machine learning in upcoming blog posts. To make sure you never miss an entry in the series, check back on our website in the coming weeks or contact us and let us know you want to start receiving our exclusive newsletter.
Stratus Innovations Group Can Help You Leverage Machine Learning to Create Real Business Value
We’re glad you’re interested in understanding the math behind machine learning. But when you work with Stratus Innovations Group, you don’t have to worry about knowing every detail of how machine learning algorithms work. We handle the technical aspects of software development, machine learning, and more so you can focus on your business and enjoy the benefits of cloud computing.
To speak with one of our experts about how a customized cloud solution can address your business’ needs and goals, call us at 844-561-6721 or fill out our simple contact form.